
"...Overall, I highly recommend this course to anyone who owns Pio but does not feel they are getting full value out of it or using its features well; which is probably almost all users."
'If you have the dedication and commitment these guys will no doubt improve your game and help you crush.’
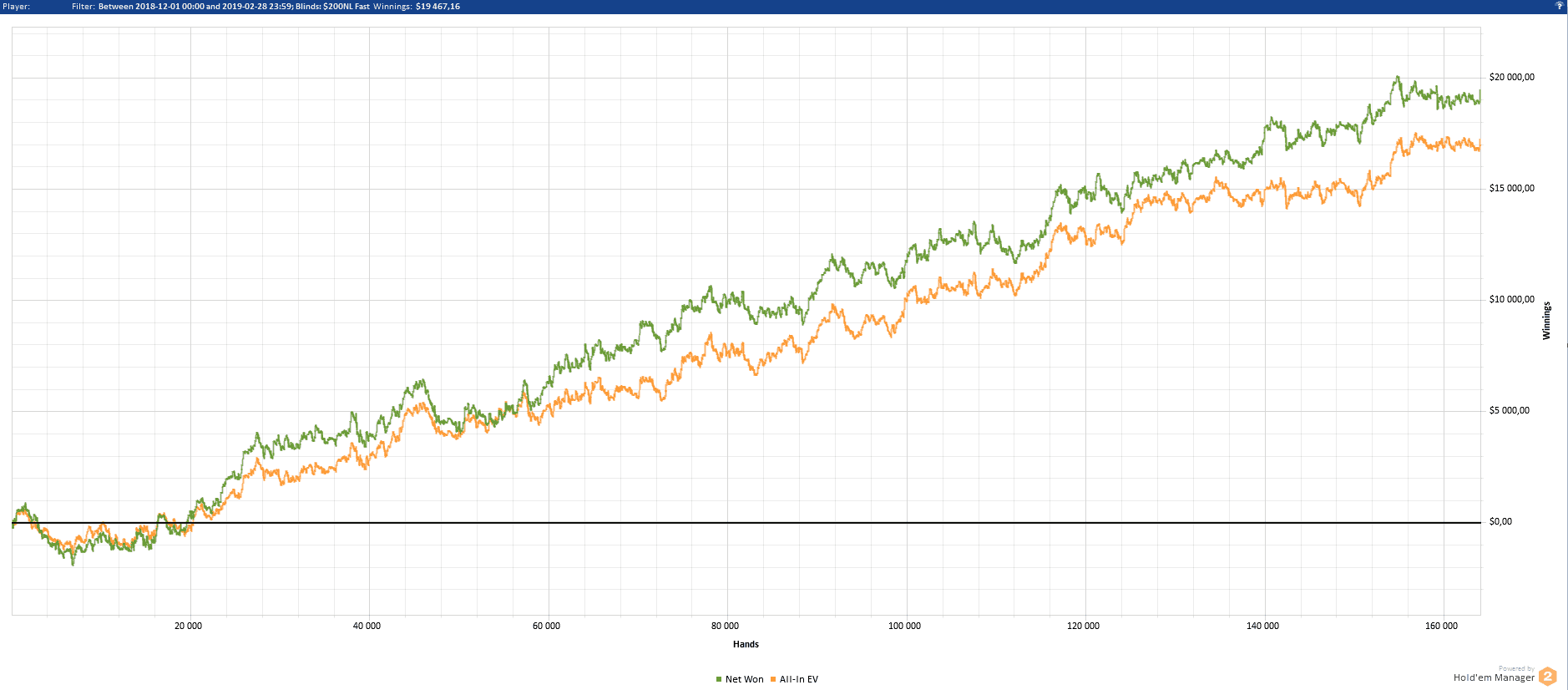
'...a perfect fit for anyone who wants to take their poker game to the next level. ‘
Concise, but gives usable heuristics and insights of how to think about blockers/combo selection.
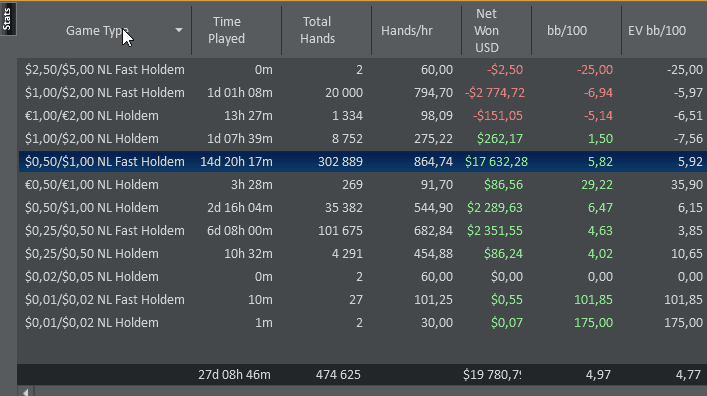
' I really enjoyed working with all the coaches. THANK YOU guys. If you're really looking to improve your game, work hard and dedicate to poker, this is really good opportunity.'
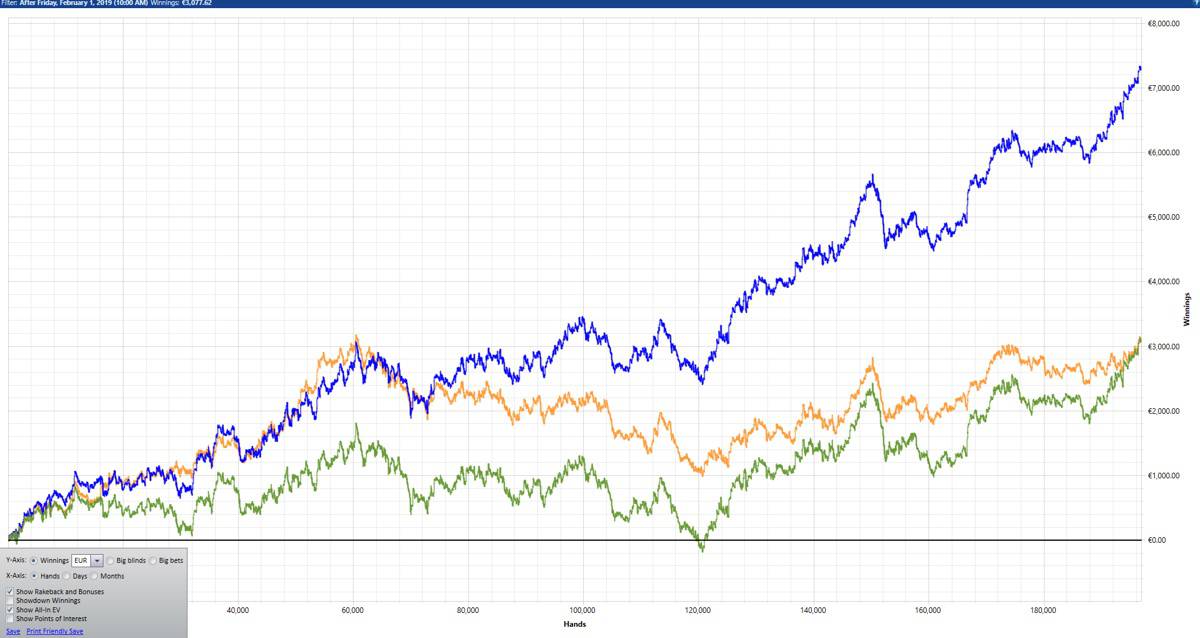
'...I feel more motivated than ever and I enjoy poker again so much that I can't stop thinking about it.'

'...now i am winning at NL100z. This progress is only over the span of 3-4 months. I can’t emphasize enough, how good these coaches are. They are very quick to spot leaks, and give you the right tools to improve immediately.'
"D7 breaks down how you should think about blockers on two-tone boards, un-blockers, and how to leverage your blockers to help with close decisions. You need not be afraid of these concepts. After just a 20 minute video, I'm sure you will feel comfortable harnessing this knowledge in your next session."
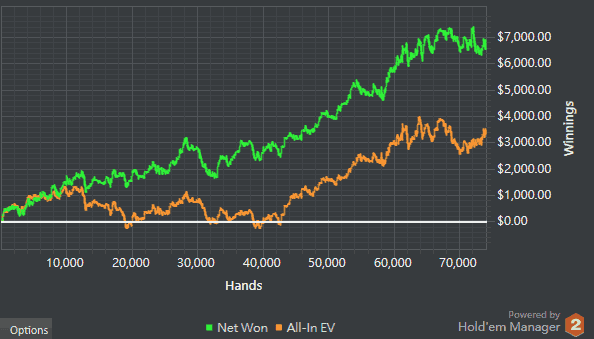
‘…Before joining bitb I was a 50z breakeven player. Now I can continue to challenge and progress at higher level. I believe that the results of these efforts need to be attributed to the selfless dedication and transparent teaching contents from the coaches…’
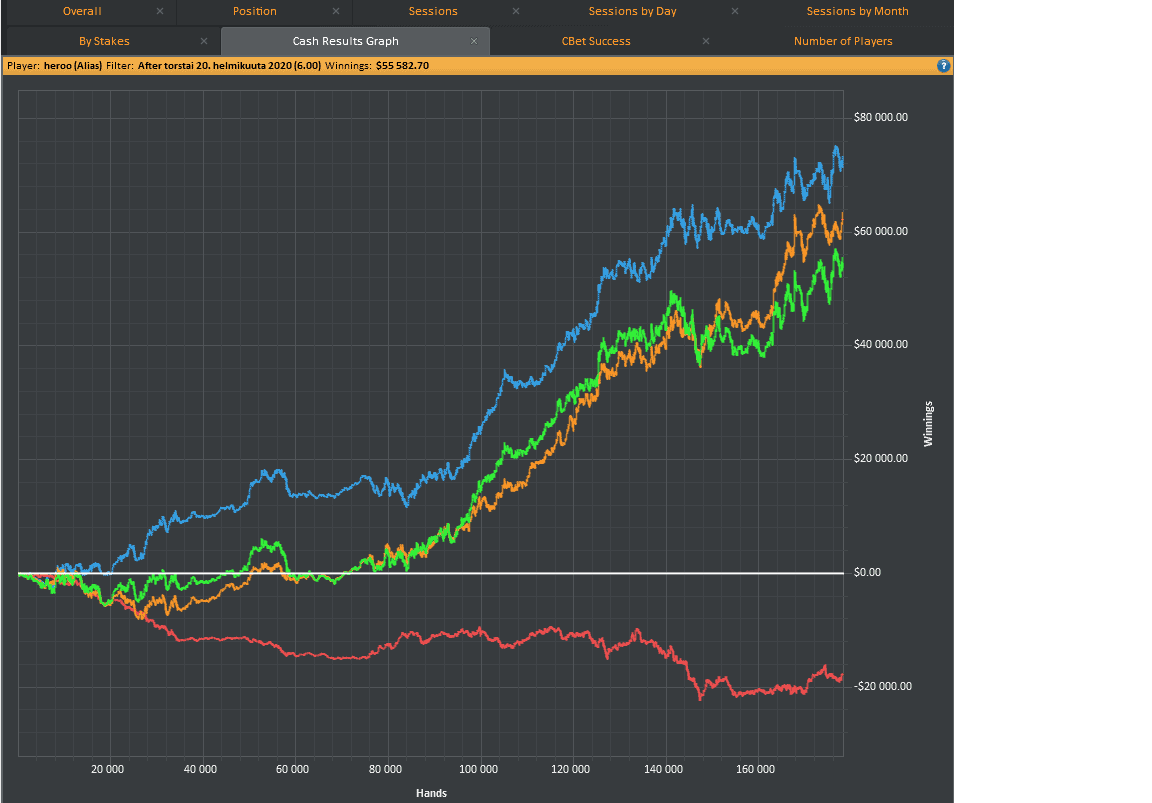
"...been playing 500/1k for two months and my general feeling is im MUCH stronger player than 4months ago..."
This is one of the best videos for my own poker game i have seen lately, it is worth every dollar and a lot more, thank you very much for the video
"Before i joined i was weakish z200 reg for years, without clear strategy how to play, without idea how to improve on my own, how to be the best pro i can be or how to learn efficiently.... 4 months later, and i play 500 comfortably, tried even a little bit of 1k ... didnt expect that to happen this soon"
"...Overall, I highly recommend this course to anyone who owns Pio but does not feel they are getting full value out of it or using its features well; which is probably almost all users."
'If you have the dedication and commitment these guys will no doubt improve your game and help you crush.’
'...a perfect fit for anyone who wants to take their poker game to the next level. ‘
Concise, but gives usable heuristics and insights of how to think about blockers/combo selection.
' I really enjoyed working with all the coaches. THANK YOU guys. If you're really looking to improve your game, work hard and dedicate to poker, this is really good opportunity.'
'...I feel more motivated than ever and I enjoy poker again so much that I can't stop thinking about it.'
'...now i am winning at NL100z. This progress is only over the span of 3-4 months. I can’t emphasize enough, how good these coaches are. They are very quick to spot leaks, and give you the right tools to improve immediately.'
"D7 breaks down how you should think about blockers on two-tone boards, un-blockers, and how to leverage your blockers to help with close decisions. You need not be afraid of these concepts. After just a 20 minute video, I'm sure you will feel comfortable harnessing this knowledge in your next session."
‘…Before joining bitb I was a 50z breakeven player. Now I can continue to challenge and progress at higher level. I believe that the results of these efforts need to be attributed to the selfless dedication and transparent teaching contents from the coaches…’
"...been playing 500/1k for two months and my general feeling is im MUCH stronger player than 4months ago..."
This is one of the best videos for my own poker game i have seen lately, it is worth every dollar and a lot more, thank you very much for the video
"Before i joined i was weakish z200 reg for years, without clear strategy how to play, without idea how to improve on my own, how to be the best pro i can be or how to learn efficiently.... 4 months later, and i play 500 comfortably, tried even a little bit of 1k ... didnt expect that to happen this soon"
much love <3
Pingback: The Ultimate Guide to GTO Poker Solvers – 3. GTO vs Exploitative Poker - Do I Need to Use a Poker Solver in 2019? - BitB Cash - Poker Training